The
concept of high availability is nothing new. For many years, network
administrators, realizing the possibility that a system can fail on any
number of levels, have attempted to mitigate that failure by providing
redundancy of system features (such as multiple disks, power supplies,
and so on) and, in the most extreme of cases, disaster recovery
methods. The goal is to make your systems fault tolerant, and failing
in that, to make your systems quickly recoverable in a disaster-like
circumstance.
High
availability comes into play as a term in the Exchange world in
absolute measurements of uptime that you strive for or offer to others
when implementing a strategy. Uptime is more than the time the system
is literally running; it implies access by a user. If a user cannot
access the system (in this case, send or retrieve email), it doesn’t
matter if it is running. It is not available.
Although
there are third-party solutions by a variety of vendors that are worth
investigating, Microsoft offers four different solutions: Local
Continuous Replication (LCR), Cluster Continuous Replication (CCR),
Standby Continuous Replication (SCR) and Single Copy Clusters (SCC).
Different techniques are used; for example, clustering might be
required. Notice, however, that in three of the solutions, the term continuous replication is used. This involves the use of a technology that is called log shipping and replay. This section explains how that works.
With continuous replication, your database is copied once. Then
all log files that are created are shipped to the secondary copy and
replayed into the duplicate database. In the event of a failure (be it
disk or system, depending on the form of continuous replication high
availability you’ve chosen), the secondary copy is ready to step in and
take over.
Each flavor of high availability is a little different. Let’s look at each one.
Note
You
might recall with Exchange 2003 that the transaction logs were 5MB in
size, but they have been reduced to 1MB. One of the reasons for this
change is that smaller logs can be transported faster and leave less
data lost if there is a problem before a log can be shipped over and
replayed.
Local Continuous Replication
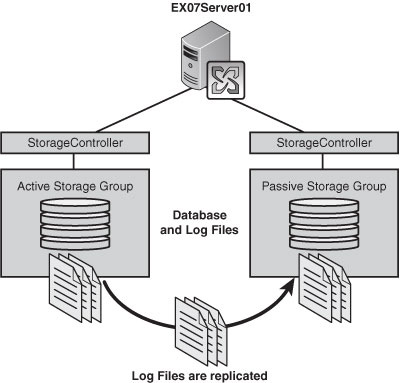
Often
called the poor man’s cluster, LCR enables you to simply place another
disk in a server and have the data mirror over using continuous
replication (with transaction log shipping and the replay technology we
discussed earlier), as shown in Figure 1.
The
positive side is that this is the cheapest solution you can implement,
requiring only an additional drive (or drives), and you can perform
volume shadow copies off the passive side of the data if you like. With
SP1 there is also a transport dumpster solution on the HT server that
allows you to recover mail that might otherwise be considered lost when
the disk fails.
The
negative side is that you aren’t running cluster services, which means
you have to manually switch from one disk to the other if a failure
occurs. The time between when the first disk fails over to when you
manually switch to the second disk is unavailable time for the server.
The other negative is that there are issues that can take place with
the system itself (such as power supply, motherboard, and network
connection) that can hinder the availability of an LCR solution.
Cluster Continuous Replication
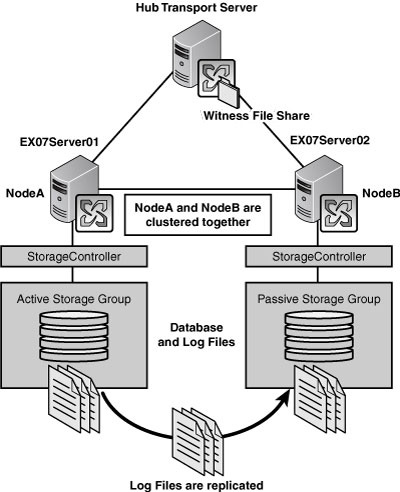
CCR
works with the same technology in that it copies the transaction logs
and replays them, but it uses cluster services from within your servers
to provide an automatic failover solution. This provides more than
automation; it also allows for a server and disk redundancy (whereas
you saw that LCR only provides disk redundancy) as you can see in Figure 2. You also have the same ability to perform a volume shadow copy off the passive copy of the data.
In
addition, there are features in place to ensure that even data that
might not be synchronized between the active and passive sides to the
cluster can be retrieved from the Hub Transport servers transport
dumpster, which retains email passing through the server for a period
of time.
On the
negative side, implementing CCR requires a knowledge of clustering
services as well as the additional hardware and software necessary to
implement it properly.
Note
You need the Enterprise edition of Windows Server to use cluster services.
Standby Continuous Replication
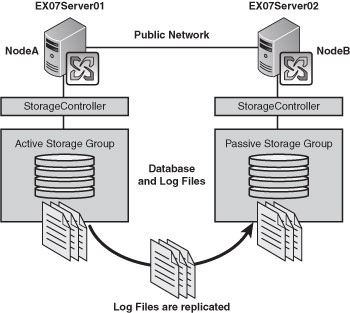
SCR
is a solution that was introduced with SP1, so it brings a fresh look
at continuous replication, where the concept is the same as LCR, log
shipping, and replay. However, rather than going from disk to disk, it
is from server to server. This doesn’t require cluster services, but it does provide the server and disk redundancy that you get from CCR, as you can see in Figure 3.
Where
the technology can become a bit intriguing is if used in conjunction
with other solutions. For example, you can use SCR to replicate a
storage group from a CCR or SCC cluster over to a remote location if
you like. Another positive feature is the built-in delay for replay
activity (which is wonderful if you want to prepare your organization
for database corruption scenarios where the delay could prevent the
corruption from making its way to the SCR copy).
From
a negative angle, you need additional hardware with software costs and
you can manage SCR only from the Exchange Management Shell (EMS). The
lack of cluster services means the automation process is out of the
picture, so you have to manually failover from the active to the
passive database, which explains why you might use SCR in conjunction
with another form of cluster high availability for that automatic
rollover in case of failure.
Single Copy Clusters
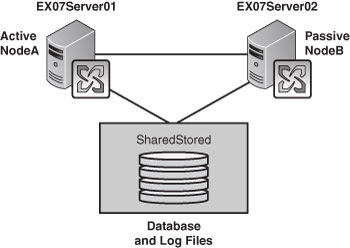
For
those who remember the Exchange 2003 high availability options with
shared storage, you will see that this is familiar. With SCC, you
cluster two servers together where they have the same shared storage
between them, as you can see in Figure 4.
The positive side here is that you have automatic failover in the event
of a server failure. The negative side is that the data has no high
availability solution in place for your SAN (although, most likely your
SAN is already prepared with some form of RAID solution in place).
Choose a High Availability Option
The
choices depend on a few simple factors. One is the size of your
organization. If you have a small environment with a single Exchange
server, it would hardly seem necessary for you to purchase a secondary
server, upgrade everything to Enterprise Edition Windows Server
software, cluster the two systems, and work out a CCR implementation.
You might do well with LCR or perhaps, depending on your environment,
with SCR.
If you have a remnant from the SAN/NAS days of shared storage that you want to keep using, you might consider SCC.
If you have a need to ensure automatic failover and you do not have shared storage, CCR is a logical solution for you.
If
you need to provide multiple levels of redundancy, you might consider a
CCR deployment with a SCR failover from one CCR cluster to another.
Cost,
need, organizational size, and level of complexity are all factors to
consider. However, the percentage of availability you wish to provide
also comes into play. If you are working with a small business, there
are times when the server doesn’t have to be online. For example, maybe
everyone leaves for the weekend and you can perform maintenance during
those periods. However, if you are setting up a hosted Exchange
environment for a huge datacenter, not only is 100% availability a
must, but you might decide to look into a third-party solution to help
provide it for you.
In the meantime, let’s take a step back and begin working on how you would set up each of these solutions.